
Juin 2025 Cloudflare a lancé "Pay Per Crawl", une nouvelle initiative qui vise à faire payer les robots d’intelligence artificielle (IA) pour accéder aux contenus web qu’ils utilisent pour s’entraîner et générer des réponses.
Ce service, actuellement en bêta privée, s’adresse principalement aux éditeurs de sites web et constitue une réponse directe aux préoccupations croissantes des créateurs de contenu face à l’extraction massive de leurs données sans compensation.
" Chez Cloudflare, nous sommes partis d'un principe simple : nous voulions que les créateurs de contenu puissent contrôler l'accès à leur travail. Si un créateur souhaite bloquer l'accès de son contenu à tous les robots d'exploration IA, il doit pouvoir le faire. Si un créateur souhaite autoriser certains ou tous les robots d'exploration IA à accéder gratuitement à son contenu, il doit également pouvoir le faire. Les créateurs doivent être aux commandes. "
Pourquoi
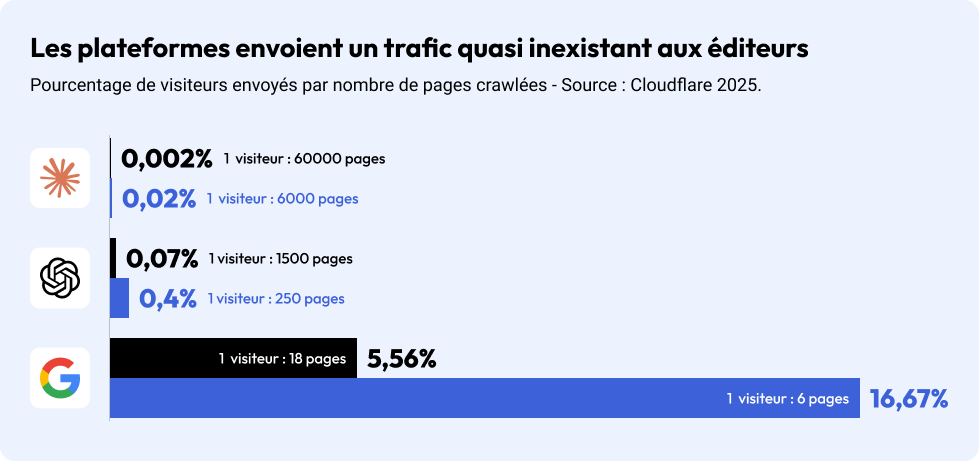
. Explosion du nombre d’utilisateurs d’Internet (de 4 à 6 milliards en 10 ans) mais diminution du trafic réel envoyé aux éditeurs : alors que Google envoyait autrefois 1 visiteur pour 2 pages crawlées, il envoie aujourd’hui 1 visiteur pour 18 pages. Pour OpenAI, c’est 1 visiteur pour 1 500 pages crawlées, et pour Anthropic, 1 visiteur pour 60 000 pages.
. Selon Matthew Prince, PDG de Cloudflare, le web risque de s’appauvrir si les créateurs ne sont plus incités à publier, notamment à cause du scraping massif par les IA sans contrepartie.
De plus en plus d’éditeurs bloquent l’accès de leurs contenus aux crawlers d’IA pour plusieurs raisons majeures :
-
Absence de retour de valeur : Les robots d’IA aspirent massivement les contenus pour entraîner leurs modèles ou répondre aux utilisateurs, mais ne génèrent quasiment aucun trafic vers les sites sources.
Par exemple, alors que Googlebot envoie environ 14 visites pour chaque page crawlée, les bots d’OpenAI ou Anthropic atteignent des ratios de 1 700:1 voire 73 000:1, ce qui signifie que le contenu est exploité sans compensation ni audience en retour. -
Menace sur le modèle économique : Pour les éditeurs qui vivent de la publicité, des abonnements ou de la vente de contenus, ce « pillage » numérique entraîne une perte directe de revenus. Les contenus monétisés sont récupérés sans autorisation, ce qui fragilise la viabilité financière des éditeurs.
-
Propriété intellectuelle et contrôle : De nombreux éditeurs souhaitent protéger leur propriété intellectuelle, contrôler l’utilisation de leurs données et choisir à qui ils accordent une licence d’accès, parfois dans l’optique de négocier une rémunération directe avec les entreprises d’IA.
-
Protection technique et expérience utilisateur : Le trafic généré par les crawlers IA peut ralentir les sites, créer des dysfonctionnements et nuire à l’expérience des vrais utilisateurs.
-
Nouvelles solutions de blocage : Des outils comme ceux de Cloudflare faciliterait le blocage automatique des bots IA, y compris via la gestion du fichier robots.txt (ca reste à voir ?), tout en laissant passer les bots utiles pour le référencement naturel (Googlebot, Bingbot).
----
Le fonctionnement de "Pay Per Crawl"
Les éditeurs ont désormais trois options :
. Autoriser l’accès gratuit de leur contenu aux crawlers.
. Faire payer l’accès, en fixant un tarif par domaine.
. Bloquer totalement l’accès aux robots IA.
Si un robot IA ne présente pas de preuve de paiement, il reçoit un code HTTP 402 “Payment Required” avec le tarif demandé. S’il paie, il accède au contenu ; sinon, l’accès lui est refusé.
> Pay per Crawl de Cloudflare
Objectifs et enjeux
. Redistribution de la valeur : permettre aux éditeurs, petits ou grands, de monétiser directement l’accès à leurs contenus par les IA.
. Limiter le scrapping sauvage : les IA devront choisir entre payer ou se passer de certains contenus, ce qui pourrait favoriser la qualité et l’originalité.
. Nouvelles stratégies pour les éditeurs : arbitrer entre visibilité dans les réponses IA et monétisation directe.
Les limites de Pay Per Crawl
. Le système ne sera efficace que si une masse critique d’éditeurs adopte ce modèle, surtout les sources les plus précieuses. Si beaucoup laissent encore leur contenu librement accessible, les IA pourront continuer à s’alimenter gratuitement.
. L’initiative ne s’applique pas aux solutions IA de Google (AI Overviews, AI Mode), qui reposent sur l’index GoogleBot, car il est peu probable que Google paie pour crawler les pages web !
Les intentions de Cloudflare
Cloudflare affirme n’avoir aucun intérêt financier direct dans ce projet, se positionnant comme défenseur du contenu original et de la souveraineté des éditeurs face à l’essor des IA génératives.
Oui mais... cela place tout de même Cloudflare en acteur central dans le contrôle de l’accès aux contenus du web.
"Pay Per Crawl" marque un tournant majeur dans la relation entre éditeurs de contenu et IA, en proposant un modèle économique pour l’accès aux données, mais son impact dépendra de l’adoption massive par les éditeurs et de la réaction des acteurs de l’IA.
Donc à suivre !
Petite note :
La fonctionnalité "Pay Per Crawl" est actuellement en bêta fermée et les propriétaires de sites intéressés peuvent s'inscrire pour participer au programme bêta.
Cloudflare utilise des solutions avancées de gestion des bots pour distinguer les crawlers d'IA des autres types de trafic, assurant ainsi que seuls les crawlers autorisés et payants peuvent accéder au contenu.
En lien avec l'article :
. En quoi les IA de Google ont de quoi inquiéter
. Web : le trafic automatisé (IA) dépasse l'activité humaine
. Moteur de recherche : Baisse du trafic organique
. Est ce qu'il faut bloquer les chatbots IA sur son site web ?



